
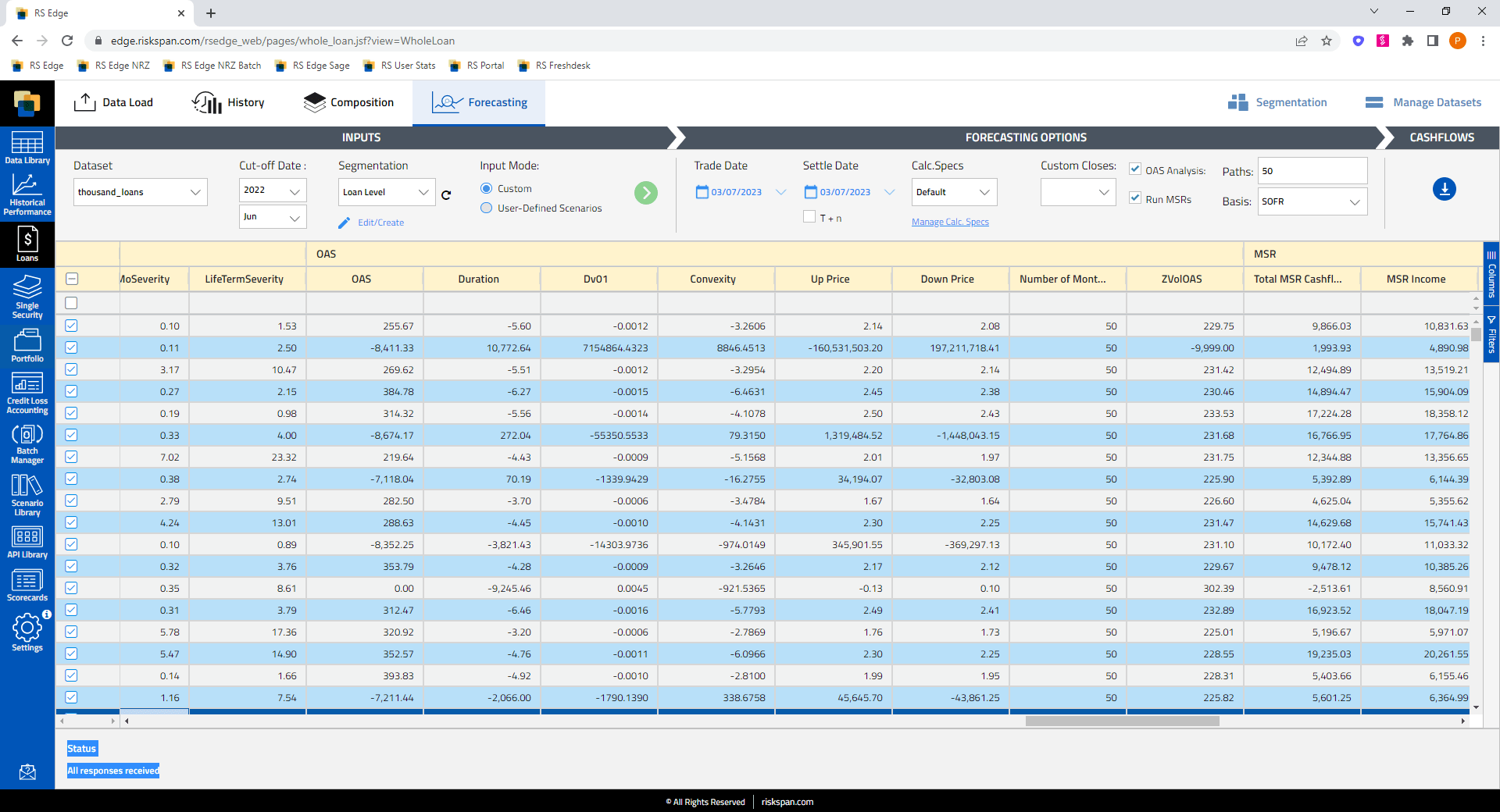
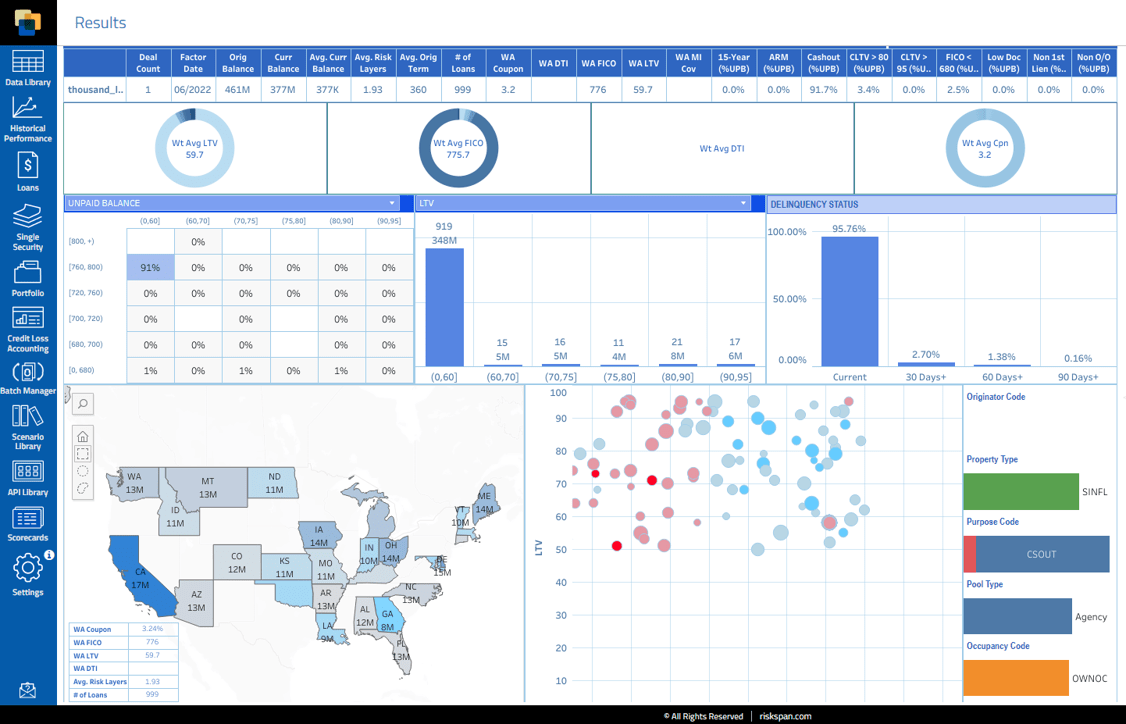
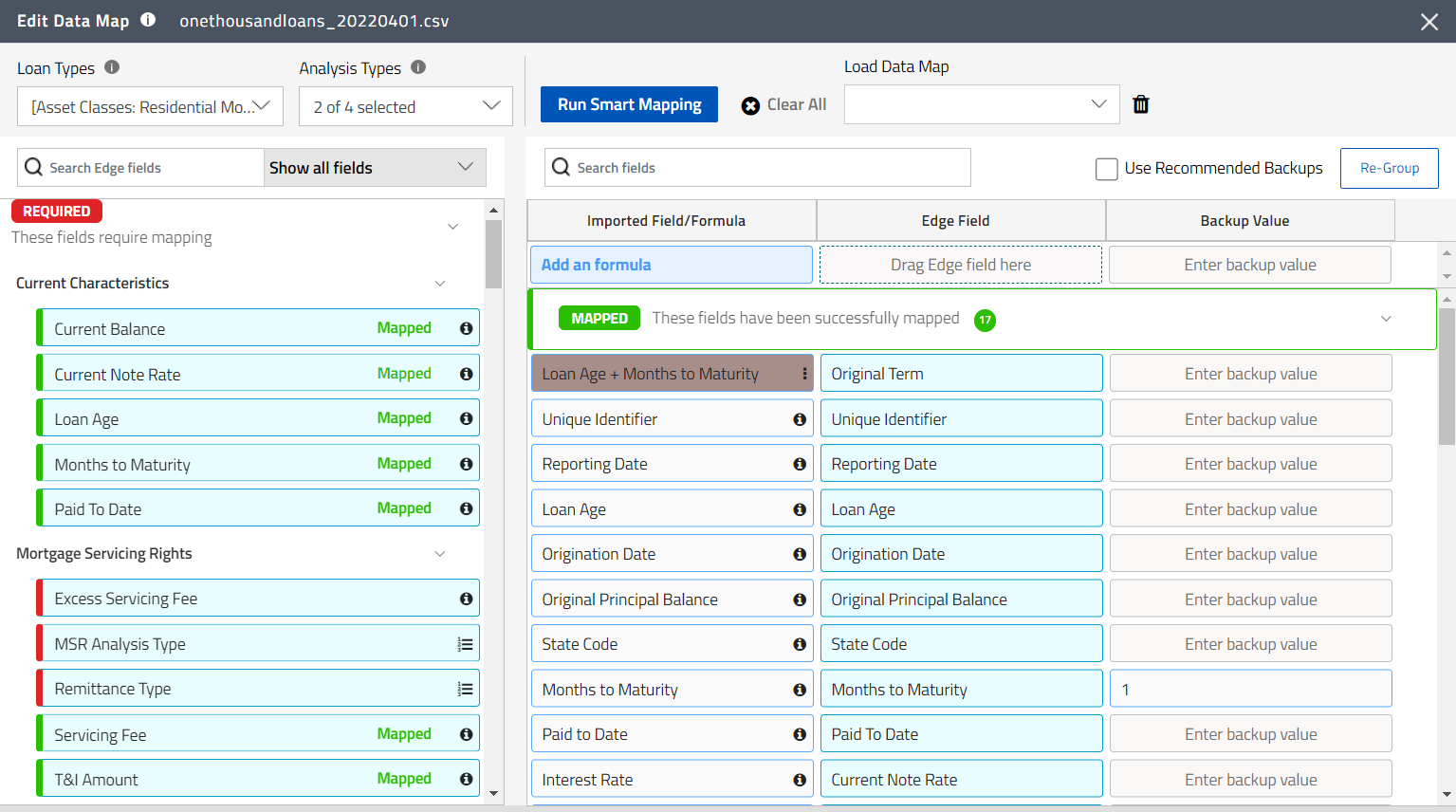
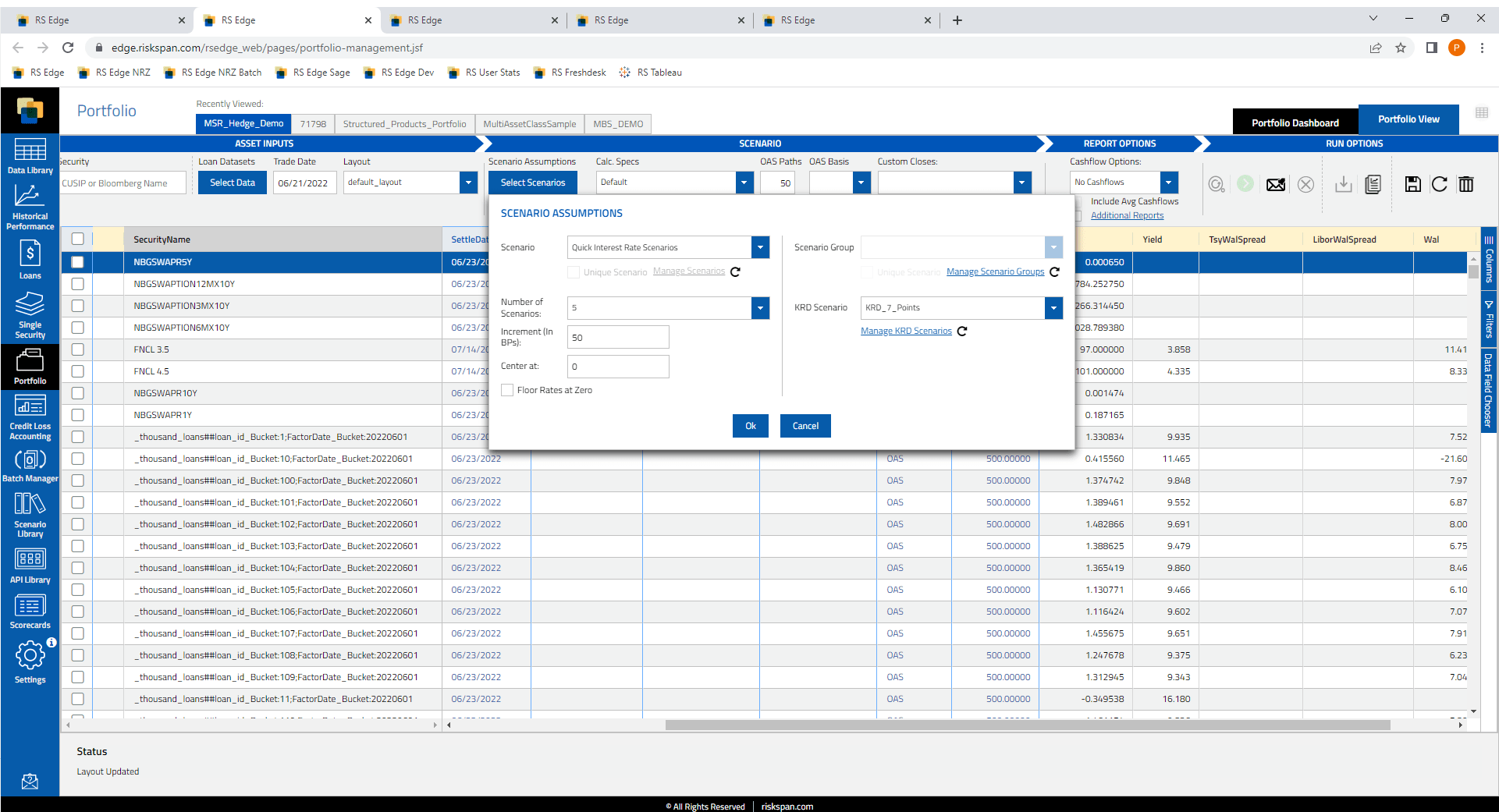
Loans and MSRs LP
(Direct Data Access via Snowflake Also Available)

Article

RiskSpan Launches Credit Model 7.1, a Purpose-Built NonQM Credit Model Insi...
Arlington, VA – July 17, 2026 – RiskSpan, a leading provider of data, modeling and analytics solutions for loan and structured finance investors, today announced the general availability of Credit

Models & Markets Update: July 2026
Register here for next month’s call: Thursday, August 20th, 2026, 1 p.m. ET. Key Takeaways Prepayment models remain reliable, but the fast bias showing up in in-the-money cohorts is worth

I Was the Cron Job: What a 1990s Back Office Taught Me About AI Token Costs...
My first Wall Street job as a junior programmer was to process pool tapes from the GSEs and Ginnie Mae. Every month, the tapes arrived and an operator loaded them.

RiskSpan Collaborates with LSEG to Power Structured Finance Evaluated Prici...
Arlington, VA – June 25, 2026 – RiskSpan, a leading provider of data, modeling and analytics solutions for loan and structured finance investors, announced their collaboration with LSEG (London Stock

Models & Markets Update: June 2026
Register here for next month’s call: Thursday, July 16th 2026, 1 p.m. ET. Key Takeaways Prepayment model continues to perform well; discount coupon speeds (WAC 5.5 and below) remain stable

The Insurance ABF Stack: Panel Takeaways
We opened the insurance panel at the RiskSpan Summit earlier this month with an interesting statistic: according to Moody’s, almost a third of the $6 trillion in cash and invested

How Mortgage Teams Are Using RiskSpan’s AI Agent to Answer MBS Data Questio...
Agency MBS data has never been more available and acting on it has never been harder. Mortgage servicers, secondary marketing desks, and risk teams are sitting on a mountain of

Models & Markets Update: May 2026
Register here for next month’s call: Thursday, June 18th 2026, 1 p.m. ET. Key Takeaways Prepayment models continue to perform well; April discount coupon speeds remain stable, driven primarily by

AI’s Uneven Impact on Labor Demands a Local Housing View
By: Scott Anderson and Bernadette Kogler AI is already disrupting parts of the U.S. labor market. The more contested question for residential mortgage investors is how and where. The dooms-day

Models & Markets Update: April 2026
Register here for next month’s call: Thursday, May 21st, 2026, 1 p.m. ET. Key Takeaways Prepayment models continue to perform well, with March speeds driven by a February rate rally

Models & Markets Update: March 2026
Register here for next month’s call: Thursday, April 16th, 2026, 1 p.m. ET. Key takeaways from this month’s call: Non-mortgage credit is deteriorating more rapidly than mortgage credit BNPL usage

From Household Debt to Non-QM Credit: February Models & Markets Recap
Register here for next month’s call: Thursday, March 19th, 2026, 1 p.m. ET. In this month’s Models & Markets call, RiskSpan’s quantitative modeling team tackled: The record debt levels now



















